本人研究课题大概可以理解为基于RASP做场景应用迁移。本来可以把开源项目拿过来用,不过目前开源的RASP都有各自的缺点,并且要把细节看懂也得花费一些时间。索性就自己写一个吧,顺便加强对JAVA的理解。
联调启动测试
将测试靶场添加作为一个module添加至agent项目当中。设置VM options:-javaagent:F:\xxx\xxx-agent\target\xxx-launcher-0.0.1.jar=xxxHome=../123;coreVersion=0.0.1即可。
BUG
type xxx not present(ClassWriter)
在hook org/apache/catalina/core/StandardWrapperValve#invoke方法时,报错Type org/apache/catalina/connector/ClientAbortException not present,看报错是ClassWriter#getCommonSuperClass方法出了问题。
ASM在计算方法的最大栈空间时会调用getCommonSuperClass方法计算给定两个类的共同父类,然而这两个类是用this.getClass().getClassLoader()得到的类加载器加载的,这里对应Launcher$AppClassLoader,在加载org/apache/catalina/core/StandardWrapperValve会加载不到,然后封装了一下抛出type xxx not present,实际上就是类加载不到。
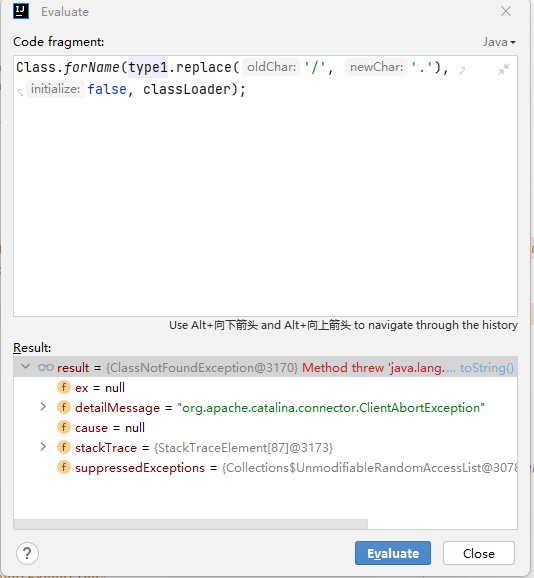
解决方案是重写getCommonSuperClass,将classLoader修改为transform方法传过来的classloader(即加载类本身的类加载器)。
@Override
protected String getCommonSuperClass(String type1, String type2) {
Class<?> class1;
try {
class1 = Class.forName(type1.replace('/', '.'), false, targetClassLoader);
} catch (ClassNotFoundException e) {
throw new TypeNotPresentException(type1, e);
}
Class<?> class2;
try {
class2 = Class.forName(type2.replace('/', '.'), false, targetClassLoader);
} catch (ClassNotFoundException e) {
throw new TypeNotPresentException(type2, e);
}
if (class1.isAssignableFrom(class2)) {
return type1;
}
if (class2.isAssignableFrom(class1)) {
return type2;
}
if (class1.isInterface() || class2.isInterface()) {
return "java/lang/Object";
} else {
do {
class1 = class1.getSuperclass();
} while (!class1.isAssignableFrom(class2));
return class1.getName().replace('.', '/');
}
}
agent共享应用运行时带的类库
在hook第三方类库时,通常需要调用该类库的方法。而rasp本身没有指定的类库故而不能方便的编写防护逻辑,如果rasp自带以来的话会有冲突问题。
解决方法一:
全部由反射解决,应用运行时是JVM是把这个类装载进去的。
解决方案二:
maven可以通过scope指定类库的作用阶段,provided表示这个库仅在开发的时候存在,在运行时这个库是不存在的。
<scope>provided</scope>
不过这么做也会有隔离的classloader加载不到应用类库的情况,需要重写类加载器来加载hook及防护逻辑。
Thread.currentThread().getStackTrace();为空
有时候会出现这个bug,原因未知。
插桩类
| ID | 大类 | 小类 | 待Hook类、方法 | 解释 | 检测方法 |
|---|---|---|---|---|---|
| 1 | 拿到用户请求信息,hook返回信息 | tomcat | org.apache.catalina.core.StandardWrapperValve#invoke | tomcat请求解析到wrapper层参数为request,response | 黑名单过滤 |
| 2 | 反序列化防护 | 原生反序列化 | java.io.ObjectInputStream#resolveClass | 反序列化readDesc拿到class通过resolveClass加载类 | 白名单放行+黑名单过滤 |
| 3 | jndi注入防护 | com.sun.jndi.toolkit.url.GenericURLContext#lookup | 都会走抽象类,检测 | 黑名单过滤 | |
| 4 | sql注入 | msql | com.mysql.jdbc.ConnectionImpl#execSQL | 无论预编译还是直接编译执行都会走到execSQL | 语义 |
| oracle | oracle.jdbc.diagnostics.Diagnosable#beginCurrentSql | 无论预编译还是直接编译执行都会走到beginCurrentSql | 语义 | ||
| sqlserver | com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement,com.microsoft.sqlserver.jdbc.SQLServerStatement | 一系列execute方法 | 语义 | ||
| pgsql | org.postgresql.jdbc.PgStatement | 一系列execute方法 | 语义 | ||
| db2 | com.ibm.db2.jcc.am | db2有些不同,这个包下的所有类都有可能是 | 语义 | ||
| 5 | 命令执行防护 | windows | java.lang.ProcessImpl#create | native method | 多种特征算法 |
| linux | java.lang.ProcessImpl#forkAndExec, java.lang.UnixProcess#forkAndExec | native method,jdk<=8的情况下会调用java.lang.UnixProcess这个类 | 同上 |
检测逻辑
命令执行
java的命令执行函数最终都会走到java.lang.ProcessImpl,在windows下调用create方法、在linux下调用forkAndExec。
值得一提的是,他们都是native方法。
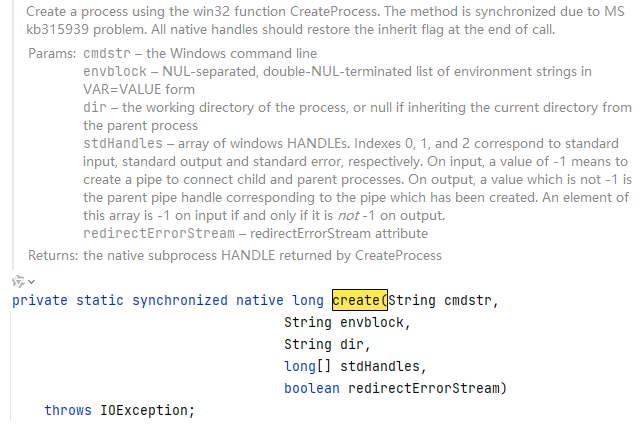
众所周知native方法不能有方法体,目前的解决方案为:
- 通过
premain/agantmain拿到instrumentation,调用inst#setNativeMethodPrefix给要调用的native方法设置一个前缀。 - 通过
ASM修改原来要hook的方法,将其修饰符修改为非native。 - 这样去掉
native的函数就可以植入监控代码,最终调用$$PREFIX$$method来调用。
不过这样也只是缓解问题,因为攻击者直接反射遍历$$PREFIX$$前缀的method然后执行就可以绕过了。
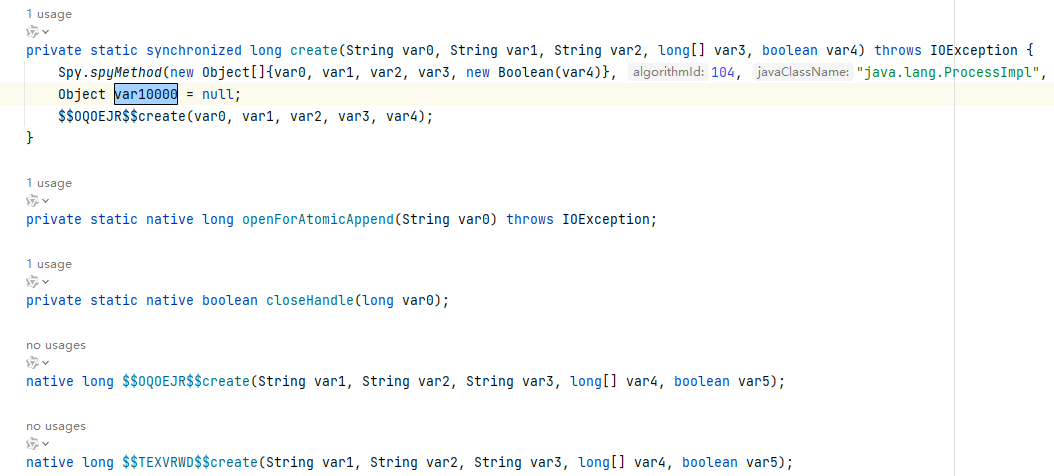
基于以上绕过方式,可以用如下方式缓解:
- 生成的前缀具备随机性,也就是说攻击者不能通过先验知识直接拿到
PREFIX。 - 通过随机生成前缀函数添加一堆虚假的
wrapper_method(一堆native),但只有一个方法是可以被调用的(执行假的wrapper_method)。这样攻击者很难找到哪个是真的(可以被JVM识别的)wrapper_method。
生成的真假美猴王:
对于检测算法来说,目前大体思路如下:
- 如果
GET、POST、HEADER参数包含要执行的命令,直接判定为后门。这块还得再考虑,因为有的后台就自带定时任务功能,这种情况也会被拦截。 - 如果执行的命令在黑名单中,那么拦截。
- 如果执行命令的调用栈在栈黑名单中,同样拦截。
- 对于执行的任意命令都记录在日志中。
jndi检测
- 黑名单过滤一些字符级的特征,很多一把嗦工具的
jndi地址有exploit,shell等特征。 - 黑名单过滤调用栈,过滤一些常见的
fastjson,yamlsink点。
sql注入
hook点有所不同,有些rasp针对最常见的数据库mysql,选择对PreparedStatement,StatementImpl插桩做不同版本的适配,但最后都会走到com.mysql.jdbc.ConnectionImpl#execSQL,所以这里hook execSQL。- 在拿到
sql语句后,用druid提供的WallUtils.isValidateXXX()做语义分析。
该方法先调用checkWhiteAndBlackList进行黑白名单检测,不过默认配置黑白名单都是空的。
首先进行词法分析,这里可以理解为分词,在这个阶段会有一些过滤,比如自动会将注释的部分删除,重新拼接SQL语句后,对”规范化”后的语句再进行注入检测,删除注释的代码逻辑在词法解析器中、不允许执行多条语句等。
之后将sql语句解析为语法树(AST树),https://www.cnblogs.com/LittleHann/p/3514532.html 这篇文章的解释很好,不过看上去druid维护一个AST树用visitor访问是为了方便统一维护规则。com.alibaba.druid.wall.WallProvider#checkInternal该方法是检测的核心功能,先根据配置情况拦截带有注释的SQL语句、堆叠查询的SQL语句,随后创建 WallVisitor,而 WallVisitor 拥有多种检查项,包括禁止变量访问或是变量黑名单、禁止永真语句、禁止黑名单函数、禁止访问黑名单表(数据库系统表)等,其中一些复杂的情况则被设置成配置选项,如禁止写文件。检测不通过则SQL语句会被加入黑名单,检测通过则SQL语句与参数化后的SQL语句都会被加入黑名单。
SQLObject:这是所有AST节点的基接口,代表SQL中的任何可识别结构。
SQLExpr (SQL表达式):扩展自SQLObject,代表SQL中的表达式,如字面量、列引用、函数调用等。
SQLIdentifier:代表SQL中的标识符,比如列名或表名。
SQLNumericLiteral:代表数字字面量。
SQLCharLiteral:代表字符串字面量。
SQLFunction:代表SQL函数调用。
SQLBinaryOpExpr:代表二元运算表达式,如加、减、乘、除等。
SQLStatement (SQL语句):同样扩展自SQLObject,代表完整的SQL语句结构。
SQLSelectStatement:代表SELECT语句。
SQLInsertStatement:代表INSERT语句。
SQLUpdateStatement:代表UPDATE语句。
SQLDeleteStatement:代表DELETE语句。
SQLSelect 和 SQLSelectQueryBlock:更具体的节点类型,用于表示SELECT查询的细节,包括查询的目标列、FROM子句、WHERE条件、GROUP BY、HAVING等。
SQLTableSource:代表数据来源,如表名、子查询或JOIN表达式。
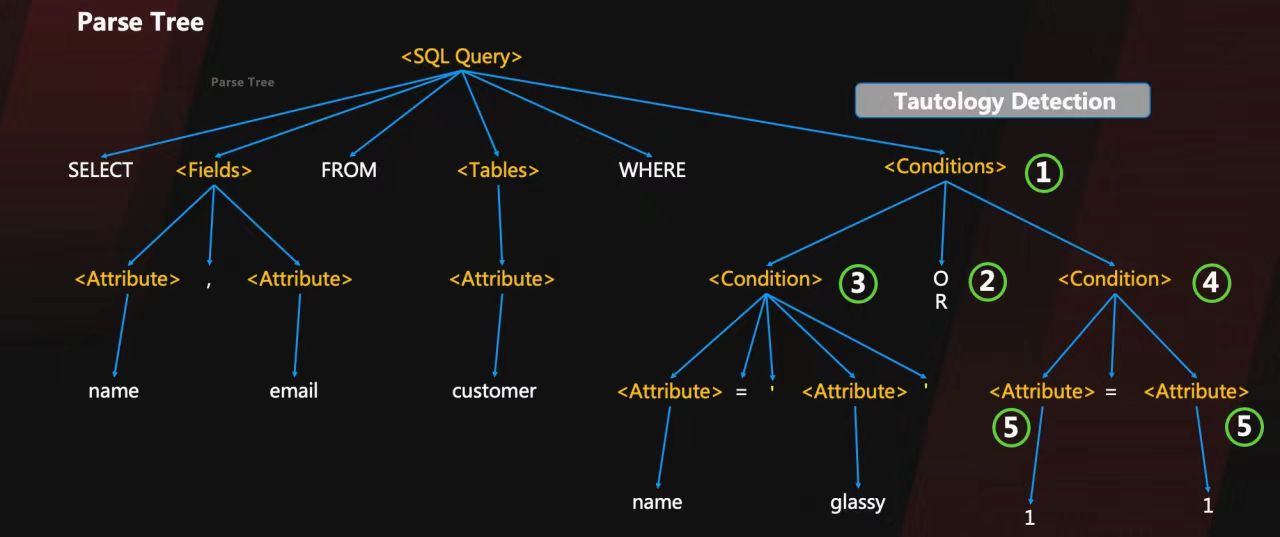
下图不是druid的防御逻辑,但感觉这种零规则检测也挺有道理的。从结构上也能看出来sql语句发生了语义偏移。